- Published on
FAILURE MODE & RECOVERY MATRIX (Outline v0.1)
- Authors
HTL-08 – FAILURE MODE & RECOVERY MATRIX (Outline v0.1)
- HTL-08 – FAILURE MODE & RECOVERY MATRIX (Outline v0.1)
- 1. Purpose
- 2. Scope
- 3. Definitions
- 4. Assumptions
- 5. System Failure Domain Overview
- 6. Failure Classification
- 7. Failure Matrix
- 8. Recovery Strategy Model
- 9. Degradation Modes
- 10. Open Issues
- 11. Revision History
1. Purpose
1.1 Document Objective
HTL-08 bertujuan untuk:
- Mengidentifikasi seluruh kemungkinan failure mode
- Menentukan metode deteksi
- Mendefinisikan dampak sistemik
- Mengunci containment boundary
- Menentukan recovery otomatis & manual
- Menetapkan escalation rule
Dokumen ini memastikan sistem tidak memiliki failure behavior yang tidak terdefinisi.
1.2 Authority
HTL-08 mengikat:
- Firmware team
- Backend team
- Electrical team
- QA team
- Field technician
Setiap failure scenario wajib memiliki owner yang jelas.
1.3 Usage
HTL-08 digunakan untuk:
- Design validation
- QA stress test
- Field troubleshooting checklist
- Risk assessment review
- Incident post-mortem analysis
Dokumen ini menjadi referensi saat terjadi insiden nyata.
2. Scope
2.1 In-Scope
Failure domain yang dianalisis:
✔ Layer Node
- Firmware crash
- Sensor anomaly
- Actuator failure
- Relay-aware topology issue
✔ Relay Chain
- Parent-child disruption
- Routing inconsistency
✔ Gateway
- ESP reboot
- MQTT failure
- Buffer overflow
✔ Server (Pi)
- Broker crash
- DB corruption
- Disk full
✔ Electrical
- Brownout
- Surge
- Overload
- Grounding issue
✔ Network
- LAN failure
- Packet loss
- IP conflict
✔ Security
- Unauthorized publish
- Replay attack
- Credential misuse
✔ OTA
- Interrupted upgrade
- Hash mismatch
2.2 Out-of-Scope
Tidak mencakup:
- Natural disaster yang menghancurkan seluruh site
- Theft seluruh panel dan infrastruktur
Namun partial theft (Node hilang) tetap in-scope.
3. Definitions
3.1 Detection
Metode atau mekanisme untuk mengidentifikasi kegagalan.
3.2 Impact
Konsekuensi terhadap sistem atau aktuator.
3.3 Recovery
Langkah pemulihan untuk mengembalikan sistem ke kondisi operasional.
3.4 Containment
Batas domain agar kegagalan tidak menyebar ke layer lain.
3.5 Escalation
Level tanggung jawab saat recovery tidak berhasil.
3.6 Safe Mode
Mode operasi dengan fungsi minimal dan aktuator dalam kondisi aman.
3.7 Partial Degradation
Sebagian sistem berfungsi, sebagian tidak.
3.8 Total Degradation
Site tetap hidup secara listrik tetapi seluruh kontrol digital tidak tersedia.
4. Assumptions
4.1 Site Semi-Autonomous
- Node tetap dapat menjalankan kontrol lokal
- Gateway atau Server bisa offline tanpa menghentikan kontrol dasar
4.2 Internet Tidak Kritikal
- Tidak ada dependency cloud
- LAN adalah satu-satunya network domain
4.3 Node Dapat Restart Sewaktu-Waktu
- Brownout
- Watchdog reset
- Firmware crash
Sistem harus toleran terhadap restart.
4.4 Power Fluktuatif
- Brownout mungkin terjadi
- Surge mungkin terjadi
- EMI mungkin terjadi
4.5 Relay-Aware Topology Terbatas
- Maks 15 node
- Hop terbatas
- Tidak ada mesh dinamis kompleks
5. System Failure Domain Overview
Tujuan section ini adalah mendefinisikan failure containment boundary agar:
- Kegagalan Node tidak menjatuhkan seluruh site
- Kegagalan Gateway tidak menghentikan kontrol lokal
- Kegagalan Server tidak mematikan aktuator
- Kegagalan elektrikal tidak merusak perangkat lain
5.1 Failure Domain Diagram
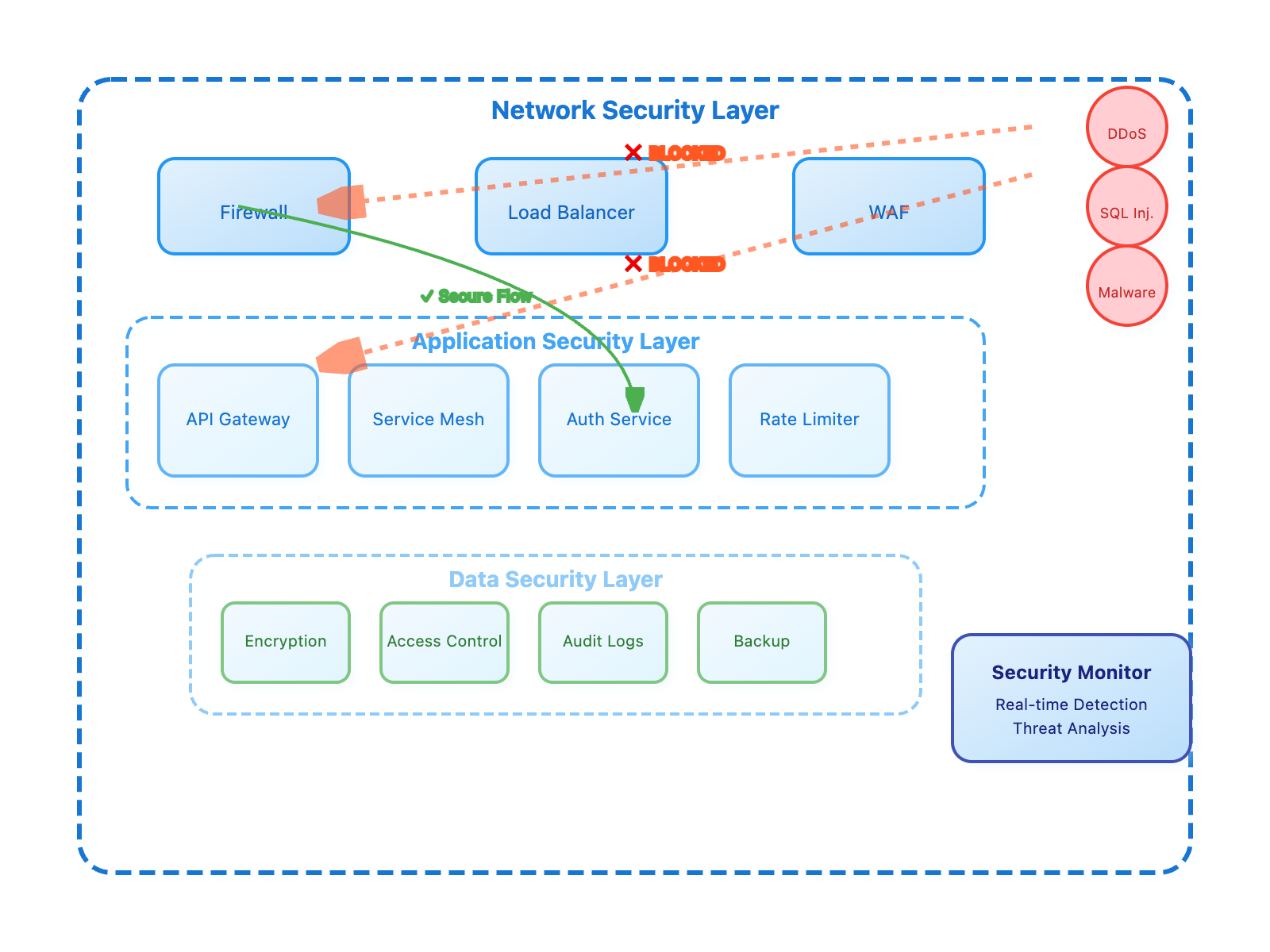
✔ Domain 1 – Electrical Layer
Komponen:
- AC input
- SMPS
- Fuse
- Relay/contact
- Panel wiring
Failure di domain ini dapat:
- Mematikan Node
- Men-trip motor
- Menyebabkan brownout
Containment:
- Fuse segmentation
- Interlock fisik
- Thermal overload
✔ Domain 2 – Node Layer
Komponen:
- ESP32 firmware
- Sensor
- Actuator driver
- Local control engine
Failure Node:
- Tidak boleh mematikan node lain
- Tidak boleh menyebabkan actuator unsafe
Containment:
- Safe state default OFF
- Interlock fisik
- Watchdog reset
✔ Domain 3 – Relay Chain Layer
Komponen:
- Parent-child routing
- Hop logic
- Sequence validation
Failure:
- Parent down
- Routing loop
Containment:
- Hop limit enforcement
- Re-route logic
- Local autonomy
✔ Domain 4 – Gateway Layer
Komponen:
- ESP-NOW coordinator
- MQTT bridge
- Buffer
Failure:
- Gateway reboot
- MQTT disconnect
Containment:
- Store-and-forward
- Node autonomy
- Automatic reconnect
✔ Domain 5 – Server Layer (Pi)
Komponen:
- MQTT broker
- DB
- Command manager
- HMI
Failure:
- Broker crash
- Disk full
Containment:
- Node autonomous mode
- Gateway buffering
- Restart service
✔ Domain 6 – User Layer
Komponen:
- Operator
- Engineer
- Admin
Failure:
- Wrong command
- Unauthorized access
Containment:
- RBAC
- TTL
- Audit log
6. Failure Classification
Semua failure diklasifikasikan untuk memudahkan QA dan analisis risiko.
6.1 Hardware Failure
Contoh:
- Relay weld
- Sensor rusak
- SMPS gagal
- ESP flash corrupt
- SD card rusak
Karakteristik:
- Fisik
- Butuh intervensi manual
6.2 Network Failure
Contoh:
- LAN down
- WiFi unstable
- MQTT disconnect
- Packet loss burst
Karakteristik:
- Biasanya temporer
- Harus auto-recover
6.3 Software Failure
Contoh:
- Firmware crash
- Deadlock service
- Memory leak
- Routing logic error
Karakteristik:
- Watchdog recovery
- Service restart
6.4 Data Failure
Contoh:
- DB corruption
- Flash corruption
- Duplicate command
- Sequence mismatch
Karakteristik:
- Harus deteksi integritas
- Recovery via restore atau re-sync
6.5 Security Failure
Contoh:
- Unauthorized MQTT publish
- Replay attack
- Credential misuse
- Firmware tampering
Karakteristik:
- Harus reject & log
- Tidak boleh memicu actuator
6.6 Environmental Failure
Contoh:
- Overheat panel
- High humidity
- EMI burst
- Voltage fluctuation
Karakteristik:
- Harus degrade safe
- Electrical protection dominan
7. Failure Matrix
7.1 Node-Level Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| N-01 | Node reboot unexpectedly | Restart counter increment | Telemetry gap | Default relay OFF | Auto reconnect | Firmware |
| N-02 | Brownout reset | Brownout log flag | Actuator OFF | Brownout threshold | Stabilize power | Electrical |
| N-03 | Sensor drift | Out-of-range persist | Wrong control decision | Plausibility check | Recalibrate/replace | Field |
| N-04 | Actuator stuck ON | Output OFF but current present | Unsafe state | Interlock hardware | Replace relay | Electrical |
| N-05 | Flash corruption | CRC fail at boot | Node safe mode | Safe mode entry | Reflash firmware | Engineer |
| N-06 | OTA interrupted | Incomplete image detect | Node reboot fail | Dual partition | Retry OTA | Engineer |
| N-07 | Parent node down | Missed heartbeat | Child unreachable | Re-route attempt | Re-pair routing | Firmware |
| N-08 | Node flooding message | Message rate anomaly | Gateway overload | Rate limit | Isolate node | Gateway |
7.2 Relay Chain Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| R-01 | Parent offline | No route ACK | Child isolated | Hop limit | Local autonomy | Firmware |
| R-02 | Child unreachable | Missing telemetry | Data gap | Routing table aging | Re-register | Firmware |
| R-03 | Hop loop detected | Duplicate seq spike | Congestion | Hop limit enforcement | Reset routing | Gateway |
| R-04 | Routing inconsistency | Conflicting parent | Unstable path | Gateway validation | Rebuild topology | Firmware |
| R-05 | Duplicate storm | Sliding window overflow | Buffer pressure | Dedup engine | Drop excess | Gateway |
7.3 Gateway Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| G-01 | Gateway reboot | Restart log | Telemetry gap | Node autonomy | Auto reconnect | Firmware |
| G-02 | MQTT disconnect | Broker state change | Data buffering | Store-forward | Reconnect backoff | Gateway |
| G-03 | WiFi down | No LAN link | Telemetry halt | Buffer local | Reconnect | Network |
| G-04 | Buffer overflow | Queue depth exceed | Data loss risk | Drop oldest policy | Increase buffer | Architect |
| G-05 | ESP-NOW congestion | High retry count | Packet loss | Rate limit | Adjust interval | Firmware |
| G-06 | Time sync failure | Drift threshold exceed | Timestamp skew | Fallback time mode | Resync | Gateway |
7.4 Server (Pi) Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| S-01 | Broker crash | Service down | No command | Node autonomy | Restart service | Backend |
| S-02 | DB corruption | Write error | Data loss risk | Ingestion halt | Restore backup | Backend |
| S-03 | Disk full | >90% usage | Write fail | Alert threshold | Cleanup/archive | Operator |
| S-04 | CPU overload | Load > threshold | Slow dashboard | No actuator impact | Optimize service | Backend |
| S-05 | Service deadlock | No response | Dashboard freeze | Service restart | Debug | Backend |
| S-06 | Power loss | Ping fail | Server offline | Node autonomy | Boot restart | Electrical |
7.5 Electrical Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| E-01 | Short circuit | Fuse blow | Actuator offline | Fuse isolation | Replace fuse | Electrical |
| E-02 | Pump overload | Overload trip | Pump OFF | Thermal relay | Reset relay | Field |
| E-03 | Relay welding | Actuator stuck | Unsafe state | Interlock | Replace relay | Electrical |
| E-04 | Surge event | SPD indicator | Device damage risk | SPD isolation | Replace SPD | Electrical |
| E-05 | Ground failure | Noise/reset | Instability | Ground correction | Fix wiring | Electrical |
| E-06 | Panel overheat | Temp > threshold | Hardware risk | Thermal shutdown | Improve ventilation | Electrical |
7.6 Network Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| NW-01 | LAN down | No ping | Dashboard offline | Node autonomy | Fix switch/router | Network |
| NW-02 | IP conflict | ARP anomaly | Device unstable | Manual isolate | Assign static IP | Network |
| NW-03 | Packet loss burst | Retry spike | Telemetry gap | QoS1 | Stabilize LAN | Network |
| NW-04 | High latency | RTT spike | Slow command | TTL control | Optimize network | Network |
7.7 Security Failures
| ID | Failure Scenario | Detection | Impact | Containment | Recovery | Owner |
|---|---|---|---|---|---|---|
| SEC-01 | Unauthorized MQTT publish | ACL violation | Command risk | Reject connection | Rotate credential | Admin |
| SEC-02 | Replay attack | Duplicate seq | Duplicate command | Sliding window | Log anomaly | Firmware |
| SEC-03 | Invalid firmware | Hash mismatch | OTA blocked | Safe mode | Reflash | Engineer |
| SEC-04 | Credential leak | Suspicious login | Unauthorized access | Account lock | Reset credential | Admin |
| SEC-05 | Excess login attempt | Threshold exceeded | Brute force risk | Lock account | Investigate | Admin |
| SEC-06 | Device cloning attempt | Duplicate device_id | Identity collision | Reject registration | Revoke device | Admin |
8. Recovery Strategy Model
Recovery dibagi menjadi tiga kategori utama:
- Automatic Recovery
- Manual Recovery
- Escalation Rule
8.1 Automatic Recovery
Dilakukan tanpa intervensi manusia.
✔ Mekanisme Wajib
- Watchdog reset (Node & Gateway)
- MQTT reconnect dengan exponential backoff
- ESP-NOW retry terbatas
- Store-and-forward flush saat broker kembali
- Safe mode entry saat firmware invalid
- Service auto-restart via systemd (Pi)
Automatic recovery tidak boleh menyebabkan actuator unsafe.
8.2 Manual Recovery
Dilakukan oleh operator/engineer.
Contoh:
- Power cycle Node
- Replace relay
- Replace sensor
- Restore DB backup
- Reflash firmware
- Re-provision device
- Replace SMPS
Semua manual recovery harus tercatat di log jika mempengaruhi sistem digital.
8.3 Escalation Rule
Level 1 – Operator
- Reset device
- Check alarm
- Replace fuse
Level 2 – Engineer
- Reflash firmware
- Replace hardware
- Restore backup
- Investigate routing
Level 3 – Architect
- Root cause systemic
- Update firmware logic
- Revise design constraint
- Update HTL document
Jika failure berulang > threshold tertentu, escalation otomatis.
9. Degradation Modes
Sistem harus memiliki mode operasi yang jelas.
9.1 Normal Mode
Semua komponen aktif:
Node ↔ Gateway ↔ Server ↔ HMI
Full telemetry & control.
9.2 Partial Mode (Gateway Down)
Kondisi:
- Gateway reboot
- MQTT unreachable
Dampak:
- Telemetry tidak sampai server
- Command dari HMI tertunda
Kontrol lokal tetap berjalan.
9.3 Autonomous Mode (Server Down)
Kondisi:
- Broker crash
- Pi power loss
Dampak:
- Tidak ada dashboard
- Tidak ada command baru
Node tetap menjalankan:
- Threshold control
- Schedule fallback
9.4 Emergency Safe Mode
Trigger:
- Firmware corruption
- Critical sensor invalid
- Brownout oscillation
- Security violation
Perilaku:
- Actuator default OFF
- Telemetry minimal
- No command execution
9.5 Degradation Mode Transition Diagram

Transisi umum:
Normal ↓ (Gateway fail) Partial ↓ (Server fail) Autonomous ↓ (Critical failure) Emergency Safe
Recovery kembali ke Normal setelah kondisi stabil.
10. Open Issues
Harus diputuskan sebelum production freeze:
- Maximum tolerable downtime per layer?
- UPS mandatory untuk Pi?
- Redundant gateway diperlukan?
- Self-healing limit (berapa retry sebelum isolate)?
- Field spare policy (berapa relay cadangan)?
- MTTR target per subsystem?
- SLA internal per-site?
Tanpa angka target, QA tidak bisa menentukan acceptance.
11. Revision History
| Version | Date | Author | Description |
|---|---|---|---|
| v0.1 | 2026-02-24 | Architect | Initial structured draft |
Catatan Penyusunan Artikel ini disusun sebagai materi edukasi dan referensi umum berdasarkan berbagai sumber pustaka, praktik lapangan, serta bantuan alat penulisan. Pembaca disarankan untuk melakukan verifikasi lanjutan dan penyesuaian sesuai dengan kondisi serta kebutuhan masing-masing sistem.